

Sponzorisane pretrage značajan su izvor prihoda internet pretraživačima. Ova vrsta reklamiranja za oglašivače predstavlja jedinstvenu priliku da dođu do korisnika čija neposredna namera pri pretrazi ima veze sa njihovim proizvodom ili uslugom.
U tipičnom scenariju kreiranja reklama, oglašivač snabdeva pretraživač nazivom svoje reklame, zajedno sa listom takozvanih “bid terms” (odnosno, pretraga/upita nakon kojih želi da se njihova reklama prikaže). Ipak, zbog velikog broja jedinstvenih pretraga, oglašivači imaju problem da pronađu svaki mogući upit koji bi bio relevantnan za njihov proizvod.
Zbog ovoga pretraživač često pruža “query-to-ad matching” uslugu, koja se sastoji od automatskog pronalaženja relevantnih upita za oglašičevu reklamu.
U novom istraživačkom radu pod nazivom "Scalable Semantic Matching of Queries of Ads in Sponsored Search Advertising" objavljenom u okviru nadolazeće 39. Međunarodne ACM SIGIR konferencije predstavljamo novi napredni query-to-ad matching pristup, zasnovan na ideji semantičnih vektora koji smo nedavno lansirali na Yahoo-ovoj platformi za sponzorisane pretrage.
Tradicionalni pristup pronalaženja relevantnih upita za datu reklamu se zasniva na nivou tekstualne bliskosti između teksta upita i teksta naslova. U našem pristupu, umesto formiranja takozvanih bag-of-words vektorskih reprezentacija upita i reklama, predlažemo mašinsko učenje vektorskih reprezentacija koristeći istoriju pretraživačkih sesija korisnika, tako da reklame i relevantni upiti budu bliski u vektorskom prostoru. Ovo olakšava računaru povezivanje upita sa reklamama na osnovu sličnosti sa naučenim vektorima.
9 milijardi sesija za treniranje algoritma
Kako bismo obučili vektorske reprezentacije reklama i upita koristili smo preko devet milijardi Yahoo Search pretraživačkih sesija. Kao što je ilustrovano na Slici 1 (levo), pretraživačka sesija definiše se kao neometan niz korisničkih aktivnosti, sačinjenih od upita (obeleženih plavo), klikova na reklame (obeleženih narandžasto) i pretraživačkih klikova na linkove (obeleženih zeleno). Ove sesije predstavljaju naše trening podatke.
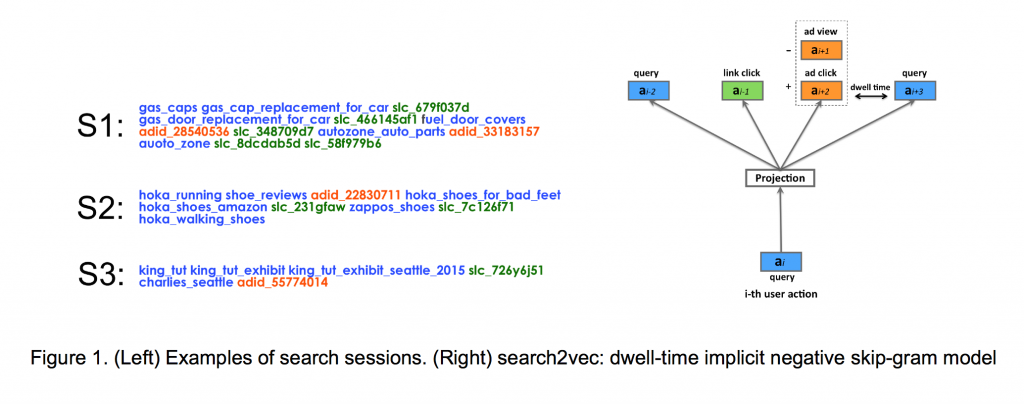
Nakon kreiranja trening podataka, naš algoritam cilja da nauči vektorske reprezentacije za svaki jedinstveni upit, id reklame, id pretraživačkog linka koristeci kontekst iz pretraživačkih sesija, odnosno njihovo direktno okruženje. Specifično, upiti, reklame i linkovi iz iste sesije koriste se kao pozitivni signal, a reklame koje su preskočene zarad klikova na reklame na nižim pozicijama koriste se kao negativni signal.
Tokom učenja vektora, bilo nam je korisno da koristimo “dwell-time”, odnosno vreme provedeno na stranici oglašivača nakon klika, da bi razlikovali “dobre” i “loše” klikove. To ukratko sumira naš model, koji smo nazvali search2vec. Njegova grafička reprezentacija je pokazana na Slici 1 (desno).
Kako bismo iskoristili pun potencijal predloženog pristupa, bilo je potrebno trenirati vektore za nekoliko miliona upita, reklama i linkova. Postojeće implementacije za treniranje semantičkih vektora nisu bili zadovoljavajući za našu ciljanu veličinu rečnika, jer oni zahtevaju da svi vektori stanu u memoriju jedne mašine. U cilju rešenja ovog problema, razvili smo novi distribuirani trening algoritam za semantičke vektore (Slika 2). Ključna novina koja je doprinela drastičnom smanjenju komunikacije između servera i klijenta je podela vektora na delove po kolonama i njihovo pojedinačno smeštanje u memorije nekoliko mašina.
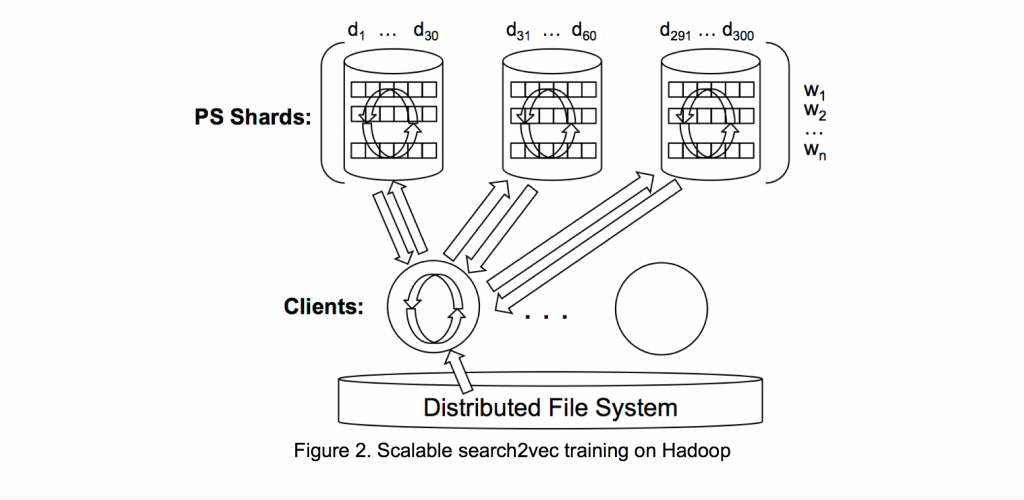
Naš search2vec sistem implementirali smo u Java-i i Scala-i na Hadoop, koristeći Slider i Spark. Sistem nam dozvoljava da treniramo semantičke vektore za više od 126 miliona jedinstvenih upita, 43 miliona jedinstvenih reklama i 132 miliona jedinstvenih linkova, što je 5 puta više u poređenju sa postojećim implementacijama koje koriste jednu mašinu.
Pronalaženje najboljih upita za reklamu
Pošto algoritam nauči vektore za upite i reklame, pronalaženje najboljih upita za specifičnu reklamu postaje pitanje računanja kosinusne sličnosti između vektora reklame i svih vektora upita, i identifikacija upita sa najvišom sličnošću. Kao što je prikazano na Slici 3, ovo nam omogućuje da pronađemo relevantne upite za bilo koju reklamu bez potrebe tekstualne obrade naslova reklame.
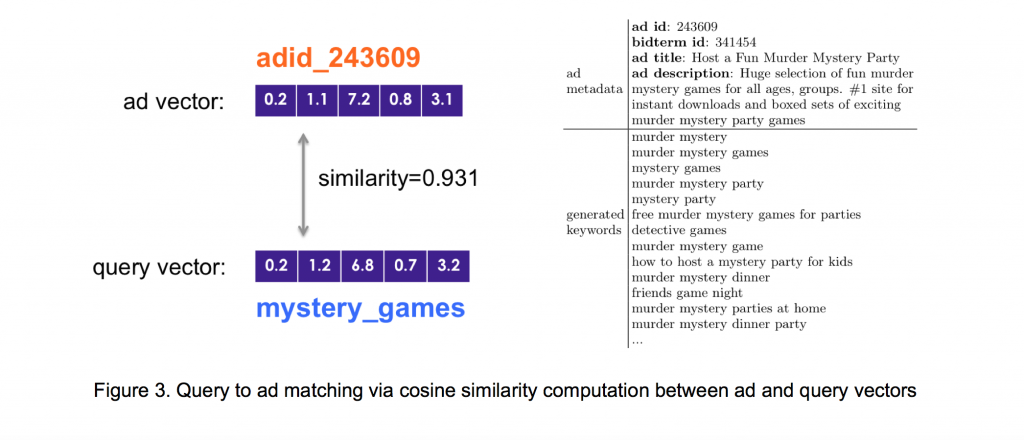
Da bismo još bolje ilustrovali kvalitet utreniranih vektora upita, predstavljamo vam demonstracioni video u kom pokazujemo kako se rezultirajućim vektorima upita može manipulisati s ciljem pronalaska sličnih upita za zadati upit. Ovaj proces je u istraživanju prirodnog jezika poznat kao “query rewriting”.
Prvo offline, pa online testovi
Lansiranje našeg search2vec algoritma za povezivanje upita sa reklamama bio je jednogodišnji projekat tima naučnika i inženjera. Kako bismo osigurali da će algoritam raditi dobro, sproveli smo seriju testova. Pre testiranja algoritma na pravom Internet saobraćaju prvo smo sproveli takozvane offline testove.
Naime, grupi ljudi smo predstavili parove reklama i upita i zamolili smo ih da ocene njihov kvalitet. U isto vreme smo izračunali kosinus sličnosti između njihovih odgovarajućih vektora koje je nas search2vec algoritam naučio. U idealnom slučaju, ljudska ocena bi trebalo da bude u korelaciji sa algoritamskom sličnošću.
Na primer, visoka sličnost bi trebalo da bude dodeljena onim parovima koje su ljudi odredili kao dobre, a niska sličnost onim parovima koji su ocenjeni kao loši. Štaviše, ukoliko ljudima damo više reklama za isti upit i pitamo za ocene, želeli smo da za isti upit naš model rangira reklame sa dobrim ocenama više nego reklame sa lošim ocenama, što smo evaluirali koristeći NDCG meru.
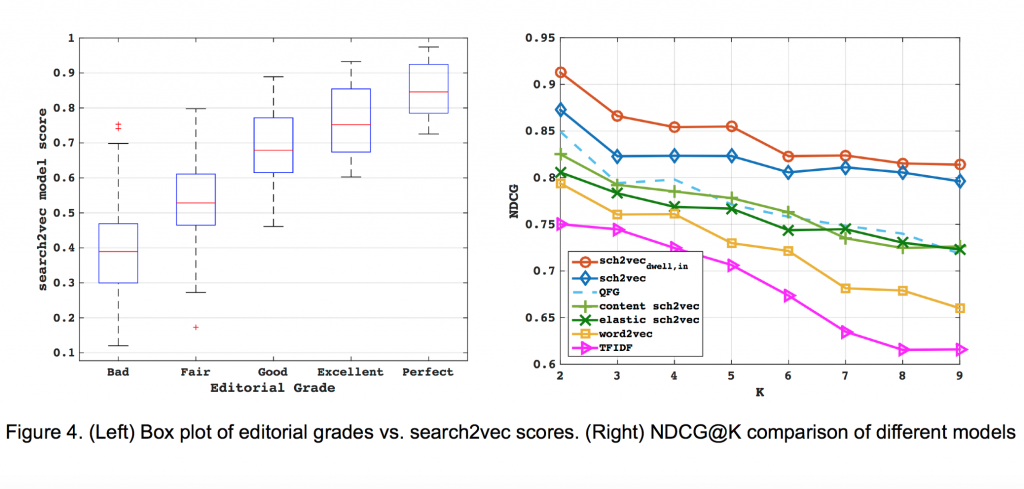
Rezultati offline testova su sumirani na Slici 4 (levo). Sa izuzetkom nekoliko parova, search2vec algoritam je bio veoma uspešan u razlikovanju različitih klasa ljudskih ocena. Dodatno, kao što možemo videti na Slici 4 (desno), search2vec uspešniji je u rangiranju reklama u poređenju sa nekoliko postojećih algoritama za rangiranje.
Nakon uspešnih offline testova, prešli smo na online testove na pravom Internet saobraćaju. Naime, sproveli smo niz A/B testova u kojima smo poredili dotadašnji algoritam za povezivanje upita i reklama sa našim search2vec rešenjem.
Prvo smo testirali search2vec model koji je treniranjem na jednoj mašini proizveo 60 miliona vektora reklama i upita. Pronalaženjem najbližih upita za svaku reklamu proizveden je rečnik koji je korišćen u A/B testu.
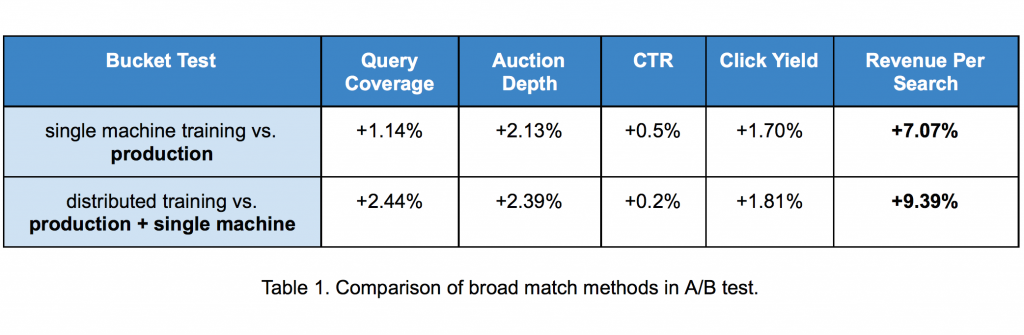
Rezultat je pokazao rast od 7% u prihodima po pretrazi i to je bilo dovoljno da lansiramo prvu verziju search2vec modela u Yahoo Search.
Narednih meseci radili smo na skaliranju veličine vokabulara kroz implementaciju distribuiranog treninga. Ovo nam je omogućilo da istreniramo više od 300 miliona vektora reklama i upita. Naš naredni A/B test je pokazao da distribuirani search2vec model može da postigne dodatni rast od 9,4% u prihodima od pretrage u poređenju sa dotadasnjim stanjem sistema (koji je ukljucivao i nas inicijalni search2vec model)
Rezultati oba A/B testa (Tabela 1) su nam dodatno pokazali da iako smo povećali pokrivenost reklama (query coverage) i dubinu aukcije (auction depth) nismo žrtvovali korisničko iskustvo, kako su nam nisu opali prosečni klikovi po pretrazi (click-through-rates).
Nakon uspešnih A/B testova, lansirali smo i našu drugu verziju search2vec sistema, sa distribuiranim treningom. Danas se search2vec redovno trenira i doprinosi više od 30% svih automatskih povezivanja upita i reklama na Yahoo Search.
Yahoo-ov doprinos vašim istraživanjima
U sklopu ovog istraživanja, 8M vektora upita koje smo trenirali pomoću naseg search2vec sistema otvorili smo za korišćenje istraživačima kroz naš Yahoo Webscope program za deljenje podataka.
Vektori mogu da posluže za testiranje novih pristupa u istraživanju prirodnog jezika. Želimo da istraživači mogu da koriste naše vektore za poređenje sa drugim pristupima za query rewriting.
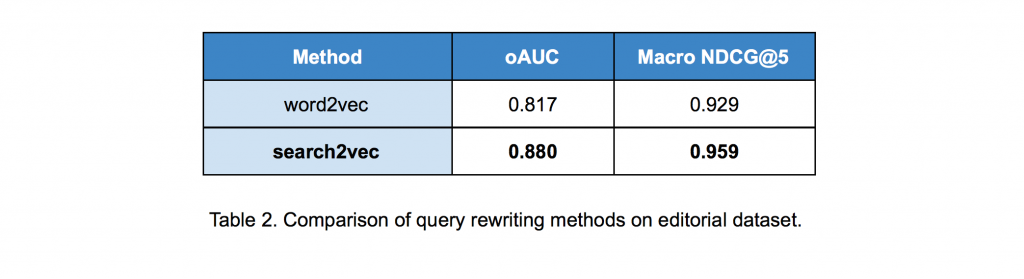
Uz vektore, odobrili smo i pristup malom query rewriting test setu od 4016 unosa čiji kvalitet je ocenjen od strane ljudskih editora. Korišćenjem ovog test seta smo uporedili performanse našeg novog search2vec modela sa postojećim word2vec modelom, a rezultati su sumirani u Tabeli 2.
Originalni tekst o istraživanju možete pronaći na Yahoo Research blogu.