

Teško je zamisliti projekat koji je baziran na mikroservisima koji nema nijednu NoQSL bazu podataka. Izgleda kao da su one preuzele dominaciju nad staromodnim relacionim SQL bazama podataka. Ipak, po rangiranju DB-Engines-a SQL baze podataka su i dalje četiri najkorišćenije (slika 1.1.), mada je to najviše zahvaljujući legacy projektima koji održavaju njihove postojeće baze i licence, a koji ne mogu da opravdaju budžet za migraciju. Ovaj zaključak može da se poveže sa grafikonom trenda (1.2.), koji pokazuje da u poslednjih šest godina najpopularnije SQL baze nisu uzele zamaha, dok su NoSQL baze u stalnom porastu.

Slika 1.1. DB rangiranje prvih 30 baza podataka
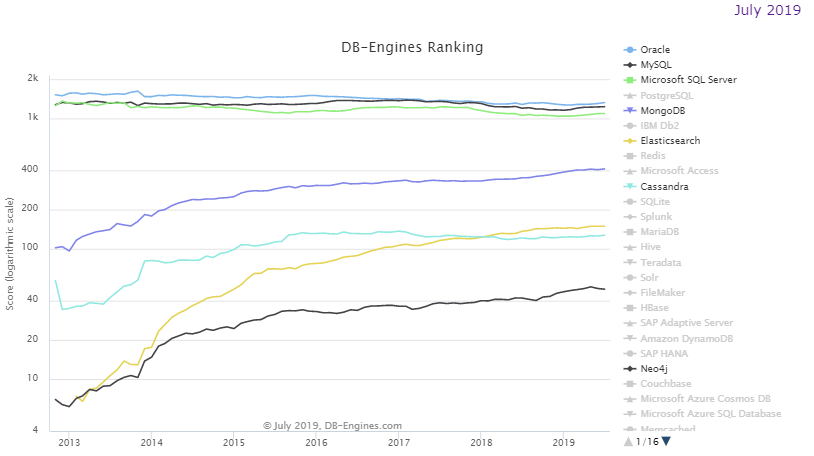
Slika 1.2. DB grafikon trenda od 2013. do jula 2019. Prve tri linije su Oracle, MySQL i MsSQL. Ispod su MongoDB, Cassandra, Elasticsearch i Neo4j.
Budući da trend raste, verovatno ćete želeti da dodate NoSQL bazu podataka u vaše mikroservis projekte — bolje pre nego kasnije. Zamislite sledeći scenario: Na projetku na kome radite, dobijate zahtev za novim setom funkcija koje semantički pripadaju jednom novom mikroservisu, i započinjete sa radom na arhitekturi. Birate Spring Boot i ostatak Spring stack-a gde god je to primenjivo, zajedno sa Spring Data kako biste apstraktovali logiku i podatke u spremišta (repository) i entitete i, konačno, morate da izaberete konkretnu Spring Data implementaciju. Za ovu potrebu možemo da ignorišemo činjenicu da Spring Data takođe ima implementacije za SQL baze podataka, koje bi više odgovarale ostatku Spring stacka-a nego Hibernate, ali ja još uvek nisam video osobu koja je izabrala SQL bazu podataka sa Spring Datom u produkciji. Umesto toga, hajde da se bolje upoznamo sa najkorišćenijim NoSQL bazama podataka i da pomognemo vama da izaberete sa kojom ćete raditi.
Brzinski kurs o osnovama NoSQL-a
Prvo moramo da napravimo digresiju i postavimo neke osnove za ovo naše igralište. NoSQL, uprkos uvreženom mišljenju, ne isključuje SQL. Zapravo, NoSQL znači: „Ne samo SQL” (“Not only SQL”). Mnoge SQL baze podataka imaju jezičku podršku nalik na SQL, zato što to ima smisla prilikom ispitivanja podataka.
Šta to, onda, razlikuje i klasifikuje NoSQL od SQL baza podataka? Sve se svodi na jednu stvar: Fleksibilnost! NoSQL baza podataka uobičajeno ne zahteva rigidnu strukturu, ne prisiljava vas da ispaštate zbog vaših odluka vezanih za dizajn i proklinjete dan kada ste tu kolonu podesili na numeric, a ne varchar… Ne, NoSQL baza podataka će želeti da bude vaš prijatelj i dozvoliće vam da usput adaptirate vaš model. Znamo da ništa u životu nije džabe, pa šta je onda cena za ovakvu funkcionalnost? Pa, bez rigidnih pravila i strukture, vaši podaci mogu da ispaštaju od nedoslednosti, a vi možete završiti sa nepovezanim podacima bez referenci, ukoliko niste veoma pažljivi u kasnijoj primeni… Sa više moći dolazi i više odgovornosti. Međutim, stvarno je vredno toga, pošto su NoSQL baze podataka de facto brže i mogu da sadrže više podataka.
Prema tome kako NoSQL baze čuvaju podatke, možemo ih podeliti na:
- bazirane na kolonama,
- bazirane na dokumentima,
- ključne vrednosti,
- bazirane na grafovima,
- multimodelne.
Spring Data je, grubim rečima, JPA za NoSQL baze podataka. Ona zapravo dodaje sloj apstrakcije na JPA, dok je implementacija ostavljena posebnim drajverima za NoSQL baze podataka. Takođe dodaje sopstvenu, vrlo kul, funkciju implementacije bez koda za obrasce spremišta (repository) i kreiranje upita (queries) baza podataka od metodnih imena.
U ovom tekstu ćemo pokriti najpoznatiju i najpopularniju NoSQL bazu podataka baziranu na kolonama — Apache Cassandra, baziranu na dokumentima — MongoDB i baziranu na grafovima — Neo4j. Podeliću sa vama neka kratka mišljenja bazirana na mojim dosadašnjim iskustvima.
Prvo, pionir — MongoDB
MongoDB baza je sa nama već neko vreme. Ove godine je, zapravo, bila njena desetogodišnjica. Ovo je razlog zbog čega je MongoDB prva baza podataka na koju se pomisli kada se priča o NoSQL. Njoj možemo i da zahvalimo za proboj NoSQL-a.
Vremenom se sigurno dosta promenila i slušala svoju veliku zajednicu. Trenutne stabilne verzije podržavaju ACID transakcije u više dokumenata, konverziju tipova i Kubernetes integraciju… Ali pre nego što dođemo dotle, hajde da pristupimo ovome iz ugla tipičnog Java+Spring Data developera.
Sve se svodi na Dokumente i JSON u MongoDB-u, a tipična baza podataka izgleda ovako:

Slika 2.1. Primer MongoDB podataka
Međutim, ukoliko koristite Spring Data, nećete moći da direktno vidite JSON-e (naravno, osim ako stvari ne krenu naopako). Kreiraćete objekte domena, mapiraćete ih pomoću Spring Data napomena (annotation) i koristićete spremišta da sačuvate podatke i dovedete ih do istrajnosti (persistance). Ukoliko stvari prođu po planu, vaša Spring Data spremišta sadržaće samo metode opisane intuitivnim imenima kao što su:
List<Person>findPersonByCountrySortByAgeAsc();
Ali, kako vaš model raste, moraćete da donosite odluke o tome kako ćete da podelite dokumente, kako ćete da napravite reference ili da li ćete koristiti grupisane dokumente (nested)... Posle nekoliko sprintova verovatno ćete imati upit u vašem Spring Data spremištu koji izgleda otprilike ovako:
@Query("{name:?0, country:?1, region:?2 , occupations: {$elemMatch: {name:?3 , status:{ $exists: false}, tasks:{ $exists: true, $not: {$size: 0} } }}}")
List<Person>findPersonByNameCountryRegionHavingAnOccupationWithTasks(String name, Stringcountry, String region, String occupationName);
Ako metod ima @Query napomene u okviru Spring Data spremišta, metodsko ime neće biti raščlanjeno tako da automatski kreira upite za baze podataka, tako da metodsko ime u ovom slučaju može da bude šta god vi smatrate odgovarajućim. U ovom trenutku verovatno razmišljate koliko bi bilo potrebno truda da samo odbacite sve postojeće podatke i remodelujete ih… MongoDB vam daje ogromnu fleksibilnost u modelovanju podataka, pa čak i ako ne osećate da model još uvek odgovara originalnoj ideji, postoji toliko funkcija u MongoDB koje mogu biti iskorišćene za upit vaših podataka, pa ćete moći da živite sa vašim izborima još neko vreme… Kako bilo, kada utonete u korišćenje projekcija i agregacija, vaši indeksi se možda više neće koristiti kako je bilo namereno, a u tom trenutku će performans ispaštati. To je sigurno trenutak kada treba da počnete da remodelujete.
Spring Data i podrška zajednice za MongoDB su zadivljujući. Vaša spremišta mogu da vrate Java 8 strimove umesto kolekcija, što vam daje fleksibilnost u podešavanju performansa. Podršku za unit testove održava zajednica, tako da ćete morati da birate između implementacija dostupnih na GitHub-u. Flapdoodle MongoDB biblioteka se pokazala kao vrlo pouzdana sa embedovanim MongoDB koji se pokreće i gasi sa vašim testovima.
Ukoliko, na kraju, morate da bacite dublji pogled na MongoDB dokumenta i JSON podatke, postoje neki odlični klijenti. Lično, ja volim RoboMongo.
Hajde da nacrtamo graf — Neo4j
Grafovi su tako praktični… Upitajte dete da vam objasni kako vidi svet i ono će verovatno nacrtati nešto što liči na graf. Upravo to je glavna udica za Neo4j: veoma je intuitivan. Ako treba da prodate Neo4j menadžmentu, biće vam potrebno dva minuta da kreirate jednostavni model koristeći neverovatnu Neo4j brauzer konzolu koja će prestavljati njihov biznis (što je prikazano na slici 3.1.). Ovako će i ne-tehnički donosioci odluka imati za šta da se uhvate, nešto što je za njih mnogo poznatije i komfornije od JSON i CSV fajlova.
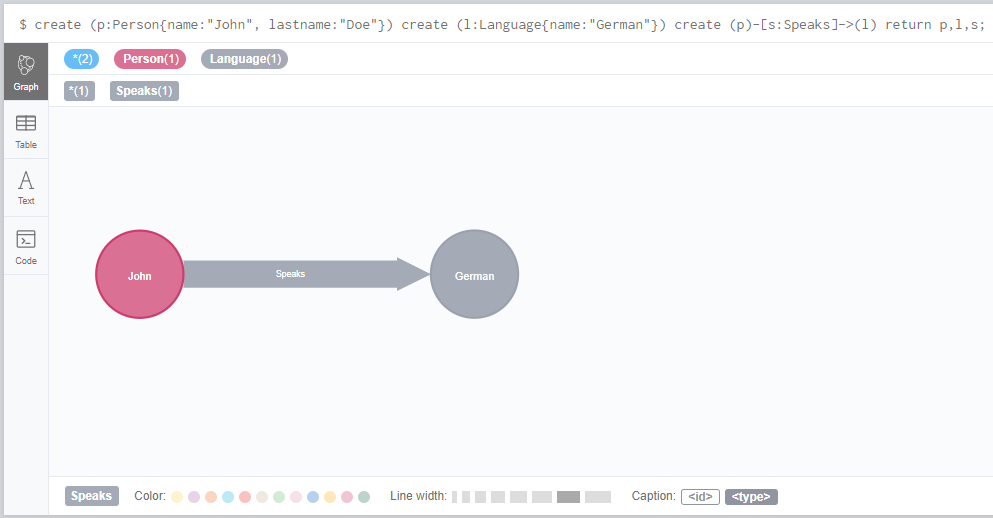
Slika 3.1. Jednostavni Neo4j grafikon kreiran korišćenjem brauzer konzole
Neo4j je u potpunosti implementiran korišćenjem Jave i Scale. Sastoji se od označenih čvorova i usmerenih tipiziranih odnosa između čvorova. Oba mogu da imaju svojstva.
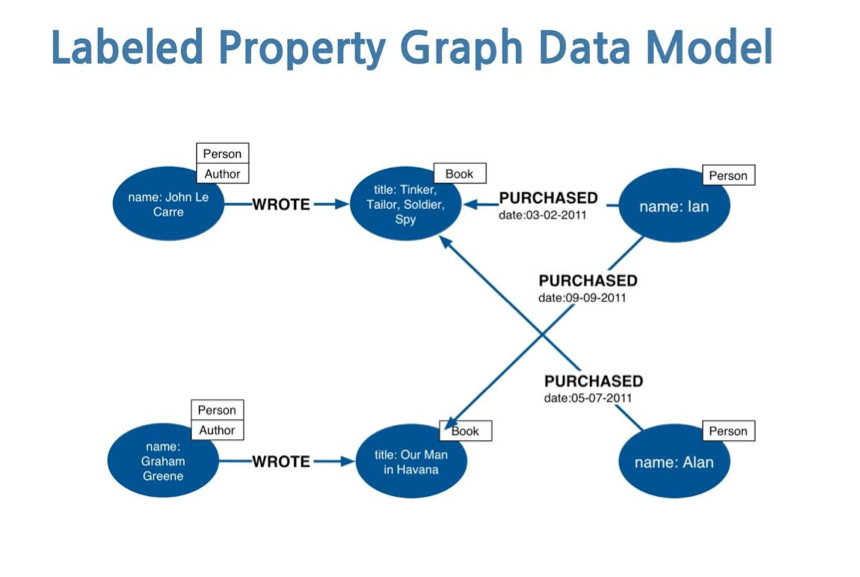
Slika 3.2. Primer grafikona modela podataka sa označenim svojstvima
U pitanju je NoSQL baza podatka, tako da je vaš model fleksibilan, a nema ni ograničenja u tome šta određeni čvor može da poseduje u pogledu svojstava i oznaka. Čvor može istovremeno da bude i Osoba i Pisac. Odnosi, sa druge strane, mogu da budu samo jednog tipa, ali nećete imati ograničenja u pogledu atributa. Ako želite da povežete više čvorova dva puta kako biste modelovali njihove veze, samo treba da stvorite dva odnosa sa različitim tipovima.
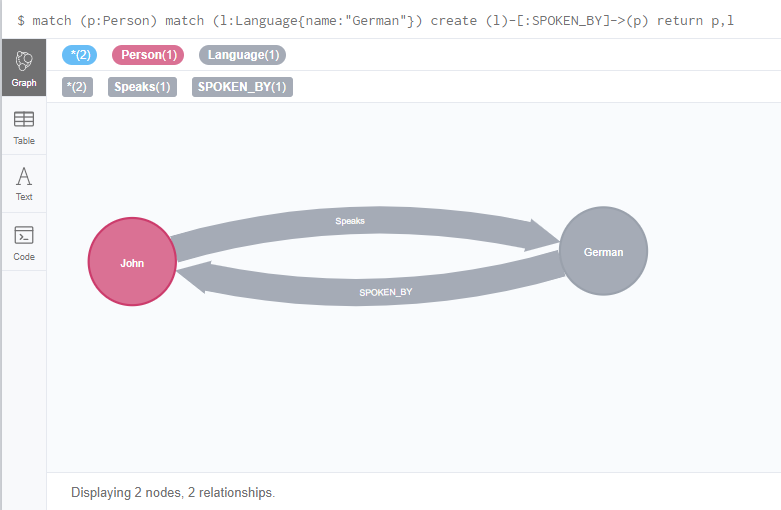
Slika 3.3. Dvostruki odnos između istih čvorova
Iako je Neo4j NoSQL baza podataka, ona podržava referencijalni integritet. Nećete moći da izbrišete čvor dokle god postoji neka veza upućena ka njemu. Tako da Neo4j kombinuje SQL i NoSQL svetove koristeći najbolje od oba: Fleksibilnost + konzistentnost i struktura. Njegov performans je takođe uvek neverovatan, naravno, ukoliko dobro modelirate vaš graf i napravite odgovarajuće indekse…
Pisanje upita u Neo4j podrazumeva korišćenje Cypher-a — jezika nalik na SQL, koji takođe pokušava da liči na graf i po svojoj sintaksi je, po mom mišljenju, sasvim intuitivan. Upiti ka osobama koje znaju nemački jezik izgledali bi ovako:
Match (p:Person)-[s:SPEAKS]->(l:Language) where l.name=”German” return p;
Teško je napisati nešto što više podseća na graf korišćenjem ASCII karaktera…
Implementacija Spring Date za Neo4j se zove Object Graph Mapper, tako da ona takođe podseća na napomene i mehanizme koje liče na Hibernate, uz implementaciju Spring Data API-a. Možete definisati entitete, odnose, slušaoce, custom mapiranje za nepodržane tipove (npr. Ako želite da ustrajete na objektu custom tipa Circle, treba da napišete vaše custom mapiranje do i od podržanog tipa kao što je String).
Mogućnosti unit testiranja su vam obezbeđeni putem zvaničnih Neo4j izdanja, tako da je vrlo lako razviti i testirati svoj kod. Ukoliko želite da imate mnogo test podataka već pripremljenih kada pokrećete embedovani test Neo4j baze podataka, možete da samo jednom kreirate podatke, a da zatim kopirate Neo4j/data folder sa hard diska u /test/resources folder i da to koristite kao izvor za test podatke.
Za optimalan rad, Neo4j zahteva količinu RAM-a koja je ista kao veličina podataka na disku, tako da kada pričamo o stotinama gigabajta, ili čak terabajta, podataka, Neo4j neće biti dobar izbori… Na sreću, ukoliko optimizujete model i razdvojite vaše biznis podatke od npr. podataka revizija, a ove druge sačuvate u npr. elastic-u, više nećete imati manjkavosti performansa ili hardvera od strane Neo4j.
Neo4j takođe ne može da postigne propusnost pisanja koja je potrebna za pokretanje u distribuiranom okruženju velikih podataka. Za ovo se može zahvaliti činjenici da će grupisani Neo4j zahtevati da se jedan čvor ponaša kao master i svi napisani upiti će ići ka njemu.
Neo4j ne podržava keyspace, ali ako stvarno želite da razdvojite podatke, ništa vas ne sprečava da paralelno pokrenete dve Neo4j instance u različitim mikorservisima...
Razmišljanje o široj slici — Apache Cassandra
A sada Cassandra… Kako je moj trenutni CTO jednom izjavio: „Ne postoji ništa na svetu što piše toliko brzo kao Cassandra.” Iako sam siguran da postoje neki perfekcionisti koji će naći primer za netačnost ove tvrdnje, ipak se slažem sa njom na osnovu svog iskustva, da je to istina za sve NoSQL baze podataka… Ili uopšte baze podataka.
Cassandra je de facto baza podataka za velike podatke (Big Data) Ali, u kom trenutku podaci postaju „veliki podaci” pa je opravdano da se Cassandra koristi za njihovo čuvanje? Radio sam sa Neo4j bazama podataka koje imaju stotine miliona čvorova, pa se one još uvek nisu kvalifikovale da budu „veliki podaci”, već su samo bile modelovani grafikoni podataka sa mnogo sadržaja. Takođe sam radio sa Mongo bazama podataka koje su narastale do desetina gigabajta, ali one nisu dolazile ni blizu toga da budu nazvane „veliki podaci”. Zato sam smislio svoju grubu definiciju: „Veliki podaci označavaju terabajte”. Ako takođe želite da imate dobar protok pisanja sa vašim Big Data bazama podataka, onda Cassandra sigurno treba da bude vaš izbor.
Zašto Cassandra nije dobar izbor za bilo šta manje od velikih podataka? Pa, da biste postigli fascinantni protok pisanja i konzistentnost podataka koje Cassandra nudi, morate da posedujete vrhunski hardver. Cassandra je uvek postavljena grupisano, dok se podaci distribuiraju preko čvorova u kružnom maniru.
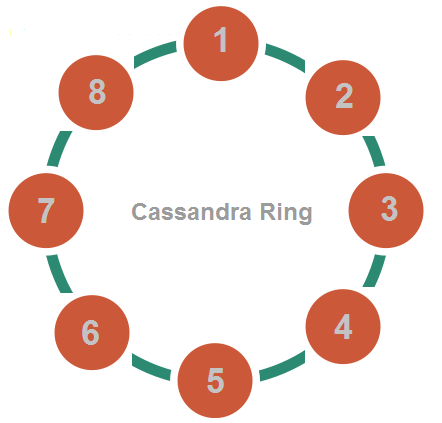
Slika 4.1. Cassandra prsten
Među ostalim opcijama za konfiguraciju kada podešavate Cassandra keyspace, možda je najveća odluka koju morate da donesete biranje faktora replikacije. Ovo određuje broj čvorova gde će replike biti postavljene. Faktor replikacije jedan znači da će postojati samo jedna kopija svakog reda u Cassandrinom prstenu. Faktor dva označava dve kopije svakog reda, gde se svaka kopija nalazi na drugom čvoru. Ovo praktično znači da ako imate faktor replikacije tri, a dva čvora prestanu da funkcionišu, još uvek ćete imati sve podatke. Naravno, cena koju plaćate za veće faktore replikacije je veća latentnost u pisanju.
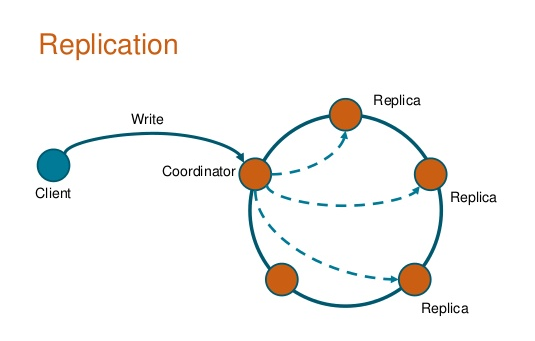
Slika 4.2. Cassandrine replikacije u pisanju
Zbog čega to Cassandra ima neverovatne performanse pisanja? Ono što je još neverovatnije je to što Cassandra ovo postiže bez korišćenja indeksa. Odgovor je deljenje podataka. Kada definišete tabelu, vi ste na neki način već definisali indeks… Morate da izabete koje kolone tabele će biti iskorišćene da se formuliš ključ po kome će se postavljati upiti.
Hajde da modelujemo osobu pomoću kolona: ime, prezime, email, adresa, godine. Najverovatniji scenario upita ovde je korišćenje imena i prezimena. Tako da ćemo kreirati tabelu u keyspace-u sa te dve kolone postavljene kao primarni ključ:
Create table example.person (name text, lastname text, email text, address text, age int, PRIMARY KEY (name, lastname));
Ovo znači da možemo slati upite o osobama sa jednostavnim SQL-om koristeći te kolone za filtriranje:
Select * from example.person where name=’John’ and lastname=’Doe’;
Uvek ćemo dobiti veoma brze rezultate. Ovo takođe znači da možemo da koristimo samo te dve kolone za upite za tabelu o osobama. Šta se dešava kada imamo email adrese, ali ne i ime i prezime? Pa, sa trenutnom tabelom ne možemo da uradimo mnogo osim da iskoristimo Spring Data da izvučemo sve redove iz Cassandre, pa da filtriramo u memoriji… Budući da smo u Big Data teritoriji, ovo verovatno neće biti jeftino za Heap… Rešenje je: kreirajte još jednu tabelu koristeži email kao primarni ključ i svaku osobu napišite dva puta.
Create table example.person_by_email (name text, lastname text, email text, PRIMARY KEY (email));
Napravićemo upit person_by_email koristeći email, a onda ćemo koristiti “name” i “lastname” koje smo dobili kako bismo napravili upit za tabelu osoba (person).
Write overhead koji smo ovde videli je uobičajen za Cassandru i tabela sa podacima će imati više tačaka ulaza, zavisno od potreba biznisa. Overhead je vrlo opravdan kada dobijete odgovor u roku od par milisekundi kada pravite upite za milione redova podataka.
I, koji je najbolji?
Kao što verovatno očekujete, ne postoji pravi odgovor. Neke prednosti i mane su date u kratkom uvodu o ove tri baze podataka.
Ako ste u teritoriji velikih podataka, Cassandra je sigurno dobar izbor, ali postoje slične baze podataka koje se nude kao servis od strane Kubernetes cloud provajdera kao što je Azure Cosmos DB.
U drugim slučajevima, odluka između MongoDB i Neo4j može da bude zasnovana na prirodi podataka: Da li odgovara grafu? Drugi faktor bi mogao da bude da li želite ograničenja (constrains), pošto vam Neo4j daje mogućnost da imate ograničenja nalik na SQL u NoSQL svetu… Ukoliko ove dve stvari ne mogu da se primene na vaše podatke, MongoDB je uglavnom brži i jede manje memorije od Neo4j.
U svakom slučaju, ništa vas ne sprečava da pokrenete Spring Boot + Spring Data mikroservis i da obe ove baze podataka isprobate zasebno. Ovo igralište je potpuno bezbedno, sve dok se ne igrate na produkcionim serverima.
Autor teksta je Danijel Gornjaković. Danijel je zaljubljenik u tehnologiju, a po zanimanju je softver developer čija je specijalnost Java. Trenutno se usavršava i u Cloud Native tehnologijama i u radu sa Big Data setovima podataka.
Tekst koji ste čitali je prevod sa engleskog jezika.