

Ako ste želeli da naučite osnove mašinskog učenja, ovaj tekst je dobro mesto za početak. Ovo je prevod prvog u nizu tekstova Adama Gajtgija na temu mašinskog učenja. Tekst u originalu možete pronaći ovde.
Da li ste nekada čuli ljude kako razgovaraju o mašinskom učenju, ali imaju samo maglovitu predstavu šta to znači? Da li vam je dosta klimanja glavom tokom razgovora s kolegama? Hajde da to promenimo!
Ovaj vodič je namenjen svakome koga zanima mašinsko učenje, ali nema predstavu odakle da počne. Pretpostavljam da je mnogo ljudi probalo da pročita članak na Vikipediji, ali se iznerviralo i odustalo, žaleći što nema nikoga da im ponudi jednostavnije objašnjenje. Ovaj vodič je upravo to.
Cilj mu je da bude razumljiv svakome – što znači da će biti mnogo uopštavanja. Ali koga briga? Ako se zbog ovoga neko još više zainteresuje za MU, misija je uspela.
Šta je mašinsko učenje?
Mašinsko učenje se zasniva na ideji da postoje generički algoritmi koji vam mogu reći nešto interesantno o skupu podataka, a da pritom vi ne morate da napišete poseban kod za taj problem. Umesto da pišete kod, vi ubacite podatke u generički algoritam, a on napravi svoju logiku na osnovu podataka.
Na primer, jedna vrsta ovakvih algoritama je klasifikacioni algoritam. On može da smesti podatke u različite grupe. Isti klasifikacioni algoritam koji se koristi da prepozna rukom napisane brojeve mogao bi da se koristi za klasifikaciju mejlova u “spam” i “nije spam”, bez promene i jedne jedine linije koda. To je isti algoritam, ali su u njega uneti različiti trening podaci, pa on smišlja različitu logiku za klasifikaciju.

Ovaj algoritam za mašinsko učenje je crna kutija — smišlja sopstvenu logiku na osnovu podataka.
Mašinsko učenje je krovni termin koji pokriva mnogo ovakvih vrsta klasifikacionih algoritama.
Dve vrste algoritama za mašinsko učenje
Algoritmi za mašinsko učenje spadaju u jednu od dve glavne kategorije – nadgledano i nenadgledano učenje. Razlika je jednostavna, ali veoma važna.
Nadgledano učenje
Recimo da ste agent za nekretnine. Posao vam raste, pa zaposlite gomilu asistenata da vam pomognu. Ali evo šta je problem – vi osmotrite kuću i već u glavi imate prilično dobru procenu koliko košta. Vašim asistentima nedostaje vaše iskustvo, pa ne znaju kako da procene kuće.
Da biste im pomogli (i možda sebi obezbedili odmor), odlučite da isprogramirate aplikaciju koja procenjuje vrednost kuće u nekom kraju na osnovu veličine, naselja u kojem se nalazi itd, i za koliko su para prodate slične kuće.
I tako tokom tri meseca vi zapisujete svaki put kada neko proda kuću u vašem gradu. Za svaku kuću zapišete gomilu detalja – broj spavaćih soba, površinu, kraj u kojem se kuća nalazi, itd. Ali što je još važnije, zapisujete i konačnu prodajnu cenu:

Ovakvi podaci nazivaju se “trening podaci”.
Koristeći ove trening podatke, želimo da napravimo program koji može da proceni koliko vredi bilo koja kuća u datom naselju:

Želimo da uz pomoć trening podataka predvidimo cene drugih kuća.
Ovo se zove nadgledano učenje. Znali ste za koliko novca je prodata svaka kuća, odnosno znali ste odgovor na pitanje, i mogli ste odatle da se vratite unazad kako biste razumeli logiku.
Da biste napravili svoju aplikaciju, ubacite trening podatke o svakoj od kuća u algoritam za mašinsko učenje. Algoritam pokušava da shvati koje matematičke operacije treba da obavi da bi brojevi imali smisla. To je kao da imate rešenja za test iz matematike, ali su aritmetički simboli izbrisani:

O, ne! Pokvareni student je izbrisao aritmetičke simbole iz nastavnikovog ključa.
Da li možete na osnovu slike da zaključite koja su pitanja bila na testu? Znate da treba da uradite nešto s brojevima levo kako biste dobili odgovore sa desne strane.
U nadgledanom učenju, vi dajete kompjuteru da to uradi za vas. A kada shvatite koje operacije su neophodne za rešavanje ovih zadataka, imate odgovore na sva pitanja ovog tipa.
Nenadgledano učenje
Hajde da se vratimo na naš prvobitni primer s agentom za nekretnine. Šta ako ne znate prodajnu cenu svake kuće? Čak iako o svakoj kući znate samo veličinu, lokaciju, i slično, i dalje možete da uradite neke prilično kul stvari. To se zove nenadgledano učenje.

Čak iako ne pokušavate da predvidite nepoznat broj (kao što je cena), i dalje možete da uradite interesantne stvari uz pomoć mašinskog učenja.
To je kao da vam neko pruži list papira sa ispisanim brojevima i kaže: „Ne znam šta ovi brojevi znače, ali možda možeš da provališ da li postoji neki obrazac ili grupisanje ili nešto slično. Srećno!“
Šta možete da uradite sa ovim podacima? Za početak, možete da napravite algoritam koji automatski identifikuje različite tržišne segmente među vašim podacima. Možda saznate da kupci u naselju blizu obližnjeg koledža baš vole male kuće s mnogo spavaćih soba, a kupci iz predgrađa više vole prostrane kuće s tri spavaće sobe. Znanje o ovim razlikama među kupcima i njihovim sklonostima može da vam pokaže kako da usmerite svoje marketing aktivnosti.
Još jedna kul stvar koju možete da uradite jeste da automatski identifikujete sve kuće koje se mnogo razlikuju od svih ostalih. Možda su to ogromne kuće, i možete svoje najbolje ljude iz prodaje da usmerite na ova naselja jer je zarada veća.
U ostatku ovog članka fokusiraćemo se na nadgledano učenje, ali ne zato što je nenadgledano učenje nešto manje korisno ili interesantno. Zapravo, s napretkom algoritama, nenadgledano učenje sve više dobija na značaju, jer se može koristiti, a da pritom ne zahteva da se podacima dodeljuju tačni odgovori.
Napomena za cepidlake: Postoji još mnogo drugih vrsta algoritama za mašinsko učenje. Ovo je, međutim, sasvim solidan početak.
Zvuči kul, ali da li se procena cene kuće zapravo može nazvati učenjem?
Ljudski mozak može da obradi gotovo svaku situaciju i da nauči kako da sa tom situacijom izađe na kraj bez konkretnih instrukcija. Ako se dugo bavite prodajom nekretnina, instinktivno ćete znati koja je odgovarajuća cena kuće, koji je najbolji način da reklamirate tu kuću, koji tip klijenta bi mogao biti zainteresovan itd. Cilj istraživanja o snažnoj AI je da omogući da se ova sposobnost ljudskog mozga omogući i na kompjuterima.
Ali, postojeći algoritmi za mašinsko učenje nisu toliko dobri – oni rade samo ako su podešeni da reše konkretan, ograničeni problem. Možda je bolja definicija učenja u tom slučaju “razumeti jednačinu kojom se rešava konkretan problem na osnovu podataka koji služe kao primer.”
Nažalost, “Mašina koja pokušava da provali jednačinu da bi rešila konkretan problem na osnovu podataka koji služe kao primer” nije baš zvučno ime. Zato koristimo “mašinsko učenje”.
Naravno, ako ovo čitate 50 godina u budućnosti i ako smo do tada već napravili algoritam za jaku veštačku inteligenciju, onda ceo ovaj članak verovatno zvuči pomalo zastarelo.
Možda, čoveče iz budućnosti, treba da prestaneš s čitanjem i kažeš svom robotu-slugi da ti napravi sendvič.
Hajde da napišemo taj program!
Dakle, kako biste napisali program koji će da proceni vrednost kuće kao u primeru s početka teksta?
Razmislite koji minut pre nego što nastavite s čitanjem.
Ako ne znate ništa o mašinskom učenju, verovatno ćete pokušati da napišete neka osnovna pravila za procenjivanje cene kuće, npr:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# U mom naselju, cena prosečne kuće iznosi $200 po m2
price_per_sqft = 200
if neighborhood == "hipsterton":
# ali neka naselja koštaju malo više
price_per_sqft = 400
elif neighborhood == "skid row":
# a neka koštaju malo manje
price_per_sqft = 100
# počnite od osnovne cene dobijene na osnovu veličine kuće
price = price_per_sqft * sqft
# sada prilagodite tu procenu prema broju spavaćih soba
if num_of_bedrooms == 0:
# studio apartmani su jeftini
price = price — 20000
else:
# kuće sa više spavaćih soba su uglavnom skuplje
price = price + (num_of_bedrooms * 1000)
return price
Ako provedete sate baveći se ovime, možda i nađete rešenje koje donekle i radi. Ali vam program nikada neće biti savršen i biće teško održavati ga kako se cene kuća budu menjale.
Zar ne bi bilo bolje kada bi kompjuter umesto vas sam mogao da shvati kako da ovu funkciju primeni? Koga briga šta funkcija tačno radi sve dok vam vraća tačan broj:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = <computer, plz do some math for me>
return price
Jedan od načina da posmatrate ovaj problem jeste da zamislite da je cena ukusni paprikaš, a da su sastojci broj soba, površina i naselje u kojem se kuća nalazi. Ako biste mogli da zaključite koliko svaki od sastojaka utiče na konačnu cenu, možda biste došli do precizne razmere sastojaka koje treba smućkati kako biste tu konačnu cenu i dobili.
Ovo bi vam skratilo prvobitnu funkciju (i poštedelo vas svih onih if-ova i else-ova), i dobili biste nešto vrlo jednostavno, na primer:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# malo ovoga
price += num_of_bedrooms * .841231951398213
# i malo više onoga
price += sqft * 1231.1231231
# možda i šaku ovoga
price += neighborhood * 2.3242341421
# i još malo soli za svaki slučaj
price += 201.23432095
return price
Obratite pažnju na magične brojeve —.841231951398213, 1231.1231231, 2.3242341421, i 201.23432095. To su nam težinski faktori. Ako bismo mogli da nađemo težinske faktore koji savršeno odgovaraju za svaku kuću, naša funkcija bi mogla da predvidi cene kuća!
Jedan od načina da nađemo najbolje težinske faktore, koji nije baš tako sjajan, bi bio na primer:
Korak br. 1:
Počnemo tako što je svakom težinskom faktoru dodeljena vrednost 1,0:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# malo ovoga
price += num_of_bedrooms * 1.0
# i malo više onoga
price += sqft * 1.0
# možda i šaku ovoga
price += neighborhood * 1.0
# i još malo soli za svaki slučaj
price += 1.0
return price
Korak br. 2:
Sada svaku kuću o kojoj imamo podatke pustimo kroz funkciju i gledamo koliko je funkcija daleko od tačne cene za svaku od kuća:
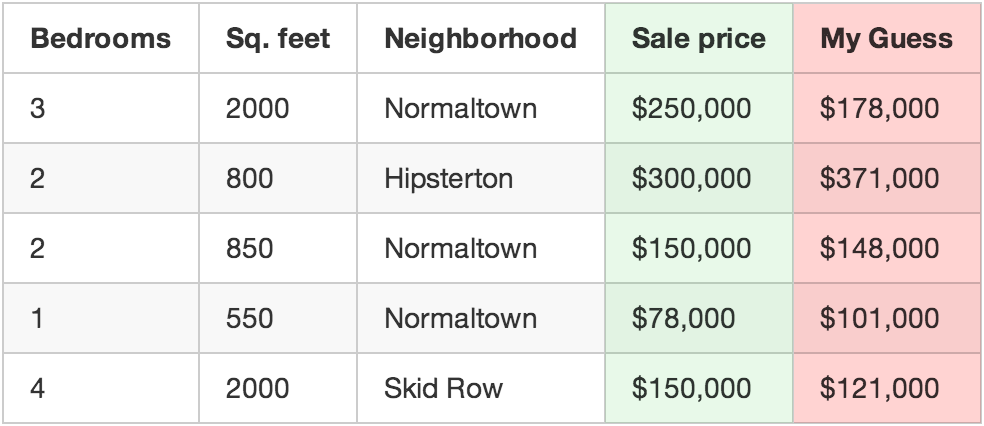
Iskoristite funkciju da predvidite cenu svake kuće.
Na primer, ako je neka kuća prodata za 250.000 dolara, a vaša funkcija je dobila 178.000 dolara, onda je to greška od 72.000 dolara, i to samo za tu konkretnu kuću.
Sada na to dodajte i kvadrat iznosa grešaka za svaku kuću koju imate. Recimo da se radi o 500 prodatih kuća, i da ukupna greška koju je funkcija napravila za sve kuće iznosi 86.123.373 dolara. Toliko trenutno vaša funkcija greši.
Sada uzmite taj ukupni iznos i podelite sa 500 da biste dobili prosečnu vrednost greške za svaku od kuća. Nazovimo ovaj iznos prosečne greške cenom u vašoj funkciji.
Ako biste, igrajući se težinskim faktorima, mogli da dođete dotle da je vrednost ove cene nula, vaša funkcija bi bila savršena. To bi značilo da je vaša funkcija za svaku od kuća pogodila cenu kuće na osnovu ulaznih podataka. Dakle, to nam je cilj – isprobavajući različite težinske faktore, treba da dobijemo najnižu moguću vrednost ove cene.
Korak br. 3:
Ponavljajte korak br. 2 dok ne ispucate sve moguće kombinacije težinskih faktora. Kombinacija prema kojoj je vrednost cene najbliža nuli je ona koju tražimo. Kada nađete faktore kojima to postižete, rešili ste problem!
Pazi sad ovo!
Ovo je veoma jednostavno, zar ne? Razmislite šta ste upravo uradili. Uzeli ste neke podatke, sproveli ste tri generička, krajnje jednostavna koraka, i dobili funkciju koja može da pogodi cenu bilo koje kuće u vašem kraju. Bolje se pripazi, Zillow!
Ali evo još nekoliko činjenica od kojih ćete zanemeti:
- Istraživanja u mnogim poljima (kao što su lingvistika/prevođenje) tokom prethodnih 40 godina pokazuju su da su ovi generički algoritmi za učenje, koji „paze da numerički paprikaš ne zagori“ (fraza koju sam upravo izmislio), bolji nego kada ljudi sami pokušavaju da formulišu konkretna pravila. Ovaj „ne toliko sjajan“ pristup mašinskog učenja naposletku dotuče žive stručnjake.
- Funkcija koju ste dobili je skroz glupa. Ona čak ne zna ni šta je to „površina kuće“ ili „spavaće sobe“. Ona samo zna da treba da pomeša neki iznos tih brojeva da bi dobila tačan broj.
- Vrlo je moguće da nećete imati predstavu zašto određeni skup faktora ispravno funkcioniše. Napisali ste funkciju koju ne razumete u potpunosti, ali za koju možete da dokažete da će raditi.
- Zamislite da umesto parametara „površina“ i „broj_soba“ vaša funkcija uzme u obzir niz brojeva. Recimo da svaki od njih predstavlja svetlost jednog piksela na slici koju je uslikala kamera koja se nalazi na krovu vašeg automobila. Recimo da, umesto izlazne vrednosti koja se zove „cena“, vaša funkcija kao izlaznu vrednost daje predikciju koja se zove „ugao_pod_kojim_treba_okrenuti_volan“.
Upravo ste napravili funkciju koja sama može da upravlja kolima!
Strava, zar ne?
Vratimo se na onaj deo o „isprobavanju svakog broja“ iz koraka br. 3.
Okej, naravno da ne možete da probate svaku kombinaciju svih mogućih težinskih faktora da biste našli dobitnu. To bi trajalo zauvek jer vam nikada ne bi ponestalo brojeva.
Da bi to izbegli, matematičari su smislili mnogo pametnih načina na koje možete brzo da nađete odgovarajuće vrednosti za te težinske faktore, a da ne morate da isprobate previše. Evo ga jedan način:
Prvo, napišimo prostu jednačinu koja predstavlja korak br. 2:
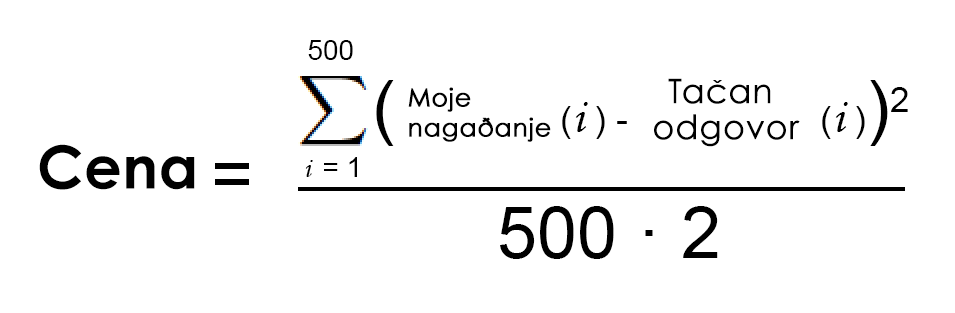
Hajde sada da opet napišemo baš istu tu jednačinu, ali uz pomoć matematičkog žargona za mašinsko učenje (koji za sada možete da zanemarite):

θ predstavlja trenutne težinske faktore. J(θ) označava „cenu trenutnih faktora.“
Ova jednačina pokazuje grešku funkcije za određivanje cene pri trenutno zadatim težinskim faktorima.
Ako napravimo grafik jednačine cene za sve moguće vrednosti naših faktora broj_spavaćih_soba i površina, dobićemo grafik koji izgleda otprilike ovako:

Grafik za našu jednačinu cene izgleda kao činija. Vertikalna osa predstavlja cenu.
Na ovom grafiku, najniža plava tačka predstavlja najnižu cenu – odnosno tu je greška naše funkcije najmanja. Dakle, ako nađemo faktore koji nas dovode do najniže tačke na ovom grafiku, eto nam ga i rešenje!

Treba samo da podesimo težinske faktore tako da „silazimo nizbrdo“ na ovom grafiku, ka najnižoj tački. Ako pravimo malu izmenu po izmenu težinskih faktora tako da se uvek krećemo ka najnižoj tački, naposletku ćemo stići tamo bez previše različitih pokušaja.
Ako se i sećate nečega iz matematike (infinitezimalnog računa), možda se sećate toga da vam izvod funkcije govori o smeru pravca tangentne linije funkcije u svakoj tački. Drugim rečima, on nam govori kuda je „naniže“ za svaku datu tačku na našem grafiku. Uz pomoć tog znanja možemo ići naniže.
Dakle, ako izračunamo parcijalni izvod naše funkcije cene za svaki od težinskih faktora, onda tu vrednost oduzimamo od svakog faktora. Tako smo korak bliže podnožju brda. Nastavimo li ovim koracima, stižemo u podnožje brda i dobijamo najbolje moguće vrednosti za naše težinske faktore (ako vam ovo nema smisla, ne brinite i nastavite da čitate).
Ovo je opšti rezime jednog od načina da se izračunaju najbolji težinski faktori za vašu funkciju koji se zove algoritam opadajućeg gradijenta. Nemojte se plašiti da zagrebete dublje ako vas zanimaju detalji. Kada koristite biblioteku za mašinsko učenje da rešite pravi problem, sve ovo će biti urađeno za vas. Ali je svejedno korisno imati jasnu sliku šta se dešava.
Koji još deo ste lukavo preskočili?
Algoritam od tri koraka koji sam opisao zove se višestruka linearna regresija.
Procenjujete jednačinu za pravu koja prolazi kroz sve tačke koje predstavljaju podatke o kućama. Onda tu jednačinu primenjujete da pogodite cene kuća koje nikada ranije niste videli na osnovu toga gde se data kuća nalazi na vašoj funkciji. Radi se o veoma moćnoj ideji koja vam može pomoći da rešite „prave“ probleme.
Ali iako pristup koji sam vam pokazao funkcioniše u jednostavnim slučajevima, neće funkcionisati u svim slučajevima. Jedan od razloga je što cene kuća nisu uvek toliko jednostavne da prate jednu pravu.
Ali, srećom, postoji mnogo načina da se to reši. Postoji još mnogo algoritama za mašinsko učenje koji mogu da koriste nelinearne podatke (kao što su neuralne mreže ili SVM koji koriste kernel). Postoje takođe i pametniji načini upotrebe linearnih regresija koji omogućavaju da upotrebite i složenije prave. U svim ovim slučajevima i dalje važi osnovna ideja da je potrebno naći optimalne težinske faktore.
Takođe, nisam se osvrnuo na ideju previše prilagođenog modela. Lako je pronaći skup težinskih faktora koji uvek savršeno predviđa cene kuća iz prvobitnog skupa podataka, ali ne funkcioniše u slučaju kuća koje nisu bile u prvobitnom skupu podataka. Ali ima načina da se i to reši (kao što su regularizacija i primena cross-validation seta podataka). Naučiti kako da rešite ovaj problem je ključni deo kada učite kako da uspešno primenite mašinsko učenje.
Drugim rečima, iako je osnovni koncept prilično jednostavan, potrebno je imati veštine i iskustvo da biste uz pomoć mašinskog učenja dobili korisne rezultate. Ali to je veština koju svaki programer može da nauči!
Da li je mašinsko učenje magija?
Jednom kada shvatite koliko je jednostavno primeniti tehnike mašinskog učenja na probleme koji deluju baš teško (kao što je prepoznavanje rukopisa), imaćete osećaj da mašinsko učenje možete da primenite za rešavanje bilo kojeg problema i da ćete, ako imate dovoljno podataka, dobiti rešenje. Samo ubacite podatke i gledajte kako kompjuter magično dolazi do jednačine koja odgovara podacima!
Ali, važno je zapamtiti da mašinsko učenje funkcioniše samo ukoliko je problem moguće rešiti uz podatke koje imate.
Na primer, ako gradite model koji predviđa cene na osnovu vrste zasađenih biljaka u svakoj od kuća, on neće funkcionisati. Prosto ne postoji veza između zasađenih biljaka u kući i njene prodajne cene. Koliko god da pokušava, kompjuter nikada neće moći da zaključi tu vezu.

Možete modelovati samo veze koje zapravo postoje.
Zapamtite, ako čovek nije mogao da iskoristi podatke da ručno reši problem, verovatno ni kompjuter neće moći. Umesto toga, fokusirajte se na probleme koje i čovek može da reši, ali gde bi bilo sjajno ako bi kompjuter mogao da ih reši mnogo brže.
Kako da naučite još toga o mašinskom učenju
Mislim da je trenutno najveći problem s mašinskim učenjem taj što se uglavnom nalazi u svetu akademika i ljudi koje se bave komercijalnim istraživanjem. Ne postoji puno jednostavnog materijala za ljude koji bi voleli da steknu širu sliku, a da ne moraju da postanu eksperti. Ali svakim danom je sve bolje.
Besplatni kurs Endrua Nga o mašinskom učenju na Kurseri je baš dobar. Preporučujem vam da krenete odatle. Trebalo bi da je razumljiv svakome ko je završio informatiku i ko se seća makar malo matematike.
Pored toga, možete da isprobate brdo algoritama za mašinsko učenje – preuzmite i instalirajte SciKit-Learn. To je okvir u python jeziku koji sadrži verziju sa „crnom kutijom“ za sve standardne algoritme.
Ako vam se svideo ovaj tekst, prijavite se na moju mejl listu Machine Learning is Fun! Slaću vam mejlove samo kada imam nešto novo i sjajno da podelim sa vama. To je najbolji način da saznate kada budem objavio još ovakvih tekstova.
Možete me pratiti na twitteru @ageitgey, poslati mi mejl, ili naći na Linkedinu.
Pišite – voleo bih da, ako mogu, pomognem vama ili vašem timu oko mašinskog učenja.
Sada nastavite na drugi, treći, četvrti i peti deo iz serije tekstova "Mašinsko učenje je zabavno"!
Dejan
sreda, 13. Februar, 2019.
Stvaro vrhunski tekst za pocetnike. Sve pohvale, drago mi je sto prevodite tekstove iskreno smatram da je bitno da na nasem jeziku postoji sto vise ovakvih clanaka
Nemanja
četvrtak, 10. Avgust, 2017.
Vau. Ali stvarno VAU, svaka čast na tekstu!
Stanislav
petak, 4. Avgust, 2017.
Ovaj članak mi je približio suštinu mašinskog učenja više nego bilo koji tekst ili video koji sam do sada prešao. Odlično napisano za nas Normalce. :)