

A/B testiranje u poslednjih nekoliko godina igra izuzetno važnu ulogu u gejming industriji, posebno nakon popularizacije free to play modela.
Ovo je metod koji se koristi kada niste sigurni o potencijalu i vrednosti novog ili redizajniranog dela igre. Štaviše, A/B testiranje je zastupljeno i u drugim oblastima — na komercijalnim sajtovima i društvenim mrežama, između ostalih.
Šta je A/B testiranje?
To je praktično primenjeno statističko testiranje — ništa više od toga. Ključna reč ovde je primenjeno. Umetnost valjanog korišćenja A/B testiranja leži u njihovoj savršenoj implementaciji, a kao što ćemo pisati kasnije u članku, ovo nije lako kao što zvuči.
Zapravo, o tome i jeste članak — pametnim trikovima i metodama koji će otključati pun potencijal vašeg A/B testiranja.
Zbog čega je bitno?
A/B testovi su popularni jer rešavaju dileme na najbolji mogući način — objektivno. Implementiraj ideju i probaj je, ništa nije bolje to toga. Ako su dobro obavljeni, pomoći će vam da donesete dobre objektivne odluke koje mogu voditi boljoj igri koja će više i zaraditi.
To znači da će svi biti zadovoljni, zar ne?
Kome je ovo bitno?
I blagoslov i kletva A/B testiranja je u tome što mnogi imaju interesa da ga koriste.
Dizajneri igara veruju da će im A/B testiranje dati odgovor na dilemu o samom dizajnu — podešavanje parametara progresije u igri, cene novih ili redizajniranih elemenata, UX odluke — ne postoji nešto što A/B testiranje ne može da sredi.
Marketari žele da optimizuju svoje kampanje; žele da znaju koje kampanje će im doneti najviše vrednosti, najjeftinije korisnike ili korisnike koji najviše plaćaju. U biznisu i menadžmentu projekata teži se unapređenju metrika zarade. Svi oni žele da među svojim oružjem imaju A/B testove.
Kako se obavlja?
Na prvi pogled, radi se o relativno jednostavnom procesu. Možemo ga podeliti u pet faza:
- Postavljanje hipoteze. Ovo može uključiti nešto tako malo poput sitnog podešavanja nekog parametra igre ili značajnog kao puštanje novog feature-a delu korisnika.
- Definisanje metrika za evaluaciju. Ovo bi trebalo da bude prirodna ekstenzija prve faze, kako se promene uglavnom prave sa krajnjim ciljem na umu i uverenjem da je potrebno unaprediti određene metrike.
- Dizajn testa bi trebalo da odgovori na pitanje: "kome i koliko dugo?". Što je trajanje testa duže i što su veće grupe, moćniji je i test, ali je i rizik veći. "Kome" deo postaje škakljiv u online PVP okruženju, i bavićemo se njime u ovom članku.
- Pokretanje testa. Test može trajati od nekoliko sati do nekoliko nedelja, u zavisnosti od faktora kao što su veličina grupe ili željena osetljivost.
- Analiziranje rezultata koristeći statističke tehnike kako biste doneli odluku o grupi koja najbolje radi.
Izazovi
Statistički šum
Statistički šum je dobro poznati neprijatelj data scientista. Po Marfijevom zakonu, visoke varijacije metrika igre uglavnom su baš one koje nas najviše zanimaju. Ovo čini naše živote težim, a naše algoritme uzorkovanja još važnijim.
Ravnopravnost u PVP igrama
Sa druge strane, statistička buka nije nešto što veliki uzorak ne može da reši. Ako imate sajt sa milionima poseta svakog dana, statistika će obaviti svoj posao i rešiti probleme sa šumom. U takvoj situaciji, milioni korisnika znače milione eksperimentalnih jedinica — svaki posetilac je nezavistan i može mu se zadati grupa bez obraćanja pažnje na ostale korisnike.
Nažalost, ako ste ponosni developeri jedne PVP igre, trebalo bi da vas brine još nešto — ravnopravnost. Naime, vaš primarni fokus bi trebalo da bude to da su ljudi koji se takmiče u online PVP okruženju izloženi istim uslovima, posebno ako ne govorimo o malim razlikama u UX-u.
Vrlo aktivan korisnik bi bio jako ljut da vidi da je njegovim protivnicima potrebno manje treninga za dostizanje trening bonusa u Top Elevenu. Ne bi bio ni previše oduševljen nefer cenama Scout igrača.
Sada, ovo poimanje ravnopravnosti prirodno razdvaja vašu bazu igrača, bez obzira koliko je velika, na manje delove. U daljem tekstu zvaćemo ih serverima.
Server = {Skup ljudi koji mogu da igraju jedni protiv drugih u online PVP okruženju}
Server može, a i ne mora biti fizički server. Može biti nivo u igri, zemlja, neka druga razdvajajuća osobina, ili fizički server. Ovo praktično znači da ne radimo sa milionima eksperimentalnih jedinica — već stotinama. Ovo dalje znači da moramo biti izuzetno, izuzetno pažljivi sa algoritmom za uzorkovanje ako ne želimo da nam test grupe budu različite čak i pre izlaganja A/B testu.
Tehnike uzorkovanja
Naš zadatak je da uzorkujemo populaciju servera, čiji red veličine se broji stotinama, na takav način da su naše grupe servera vrlo slične pre objavljivanja testa. Za potrebe primera (i snažnim korenima u stvarnosti), recimo da gledamo ka ARPDAU (Average Revenue Per Daily Active Users) kao glavnoj metrici.
Nasumično i stratifikovano nasumično uzorkovanje
Počeli smo sa tradicionalnim nasumičnim uzorkovanjem, ali je bilo očigledno da sa ovako malom populacijom, ono neće raditi.
Prva ideja za unapređenje ovoga bila je da pokušamo sa stratifikovanim random uzorkovanjem, gde razdvajamo servere u one sa niskim ARPDAU, srednjim ARPDAU i visokim ARPDAU, i uzorkujemo nezavisno iz te tri grupe.
Kao što je očekivano, bilo je malo bolje, ali i dalje, ni blizu zadovoljavajućem. Morali smo ovo da ponavljamo i vizuelno istražujemo sličnosti grupa - nepraktično i dosadno.
Sistematsko uzorkovanje
Nastavili smo dalje, tražeći bolje rešenje. Ponovo, za potrebe primera, recimo da želimo da uzorkujemo dve grupe deset servera za A/B testiranje. Naša naredna ideja je da uzorkujemo parove servera na sledeći način:
- Uzorkujemo server 's' nasumično i pripišemo ga grupi A;
- Odaberemo server koji je najsličniji serveru 's' i dodelimo ga serveru B;
- Ponovimo 10 puta.
Ovo bi trebalo da radi na osnovu zapažanja da ako su svi parovi jako slični, dve grupe ovako kreirane trebalo bi da budu slične. Ovo dobro radi kada radimo samo sa jednom metrikom.
Šta se dešava ako želimo da pratimo više od jedne izlazne metrike — recimo njih pet (što je veoma realistično)? Zbog kletve dimenzionalnosti, postaje sve teže pronaći parove izuzetno sličnih servera u populaciji stotina. Moramo pronaći bolji način da poništimo ove razlike tako što ćemo uzorkovati na pametan način.

Novi pristup — Optimalno uzorkovanje
Ideja je bila da odustanemo od random uzorkovanja i počnemo da optimizujemo. Zašto ne bismo kreirali najsličnije moguće grupe? Bukvalno!
Bez nasumičnog uzorkovanja — odaberimo ih optimalno. Imamo pristup podacima iz prošlosti. Za svaku odabranu metriku, svaki server, svaki dan, imamo vrednost i možemo te podatke koristiti da odaberemo grupe sa najmanje razlika.
Drugim rečima, možemo rešiti problem optimizacije korišćenjem cost funkcije koja kažnjava sve razlike između grupa. Ovu optimalnu tačku pronalazimo korišćenjem izuzetno jednostavnog algoritma za optimizaciju.
Algoritam
Definisanje cost funkcije
Definisali smo cost funkciju u — za one koji se poznaju mašinsko učenje — prirodnom, L2 maniru. Penalizujemo kvadratnu razliku između grupa za svaku metriku i za svaki dan prošlih podataka. Na ovaj način i uspomoć procedure za optimizaciju, pokušaćemo da pronađemo optimalne grupe.
Cost funkciju definišemo na sledeći način:
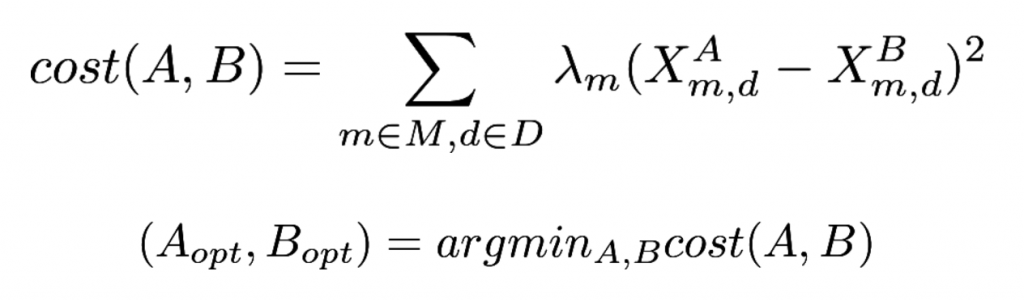
M je set svih KPI koji nas interesuju, D je set svih istorijskih podataka na kojima optimizujemo grupe, lambde su težine važnosti koje koristimo da oslovimo važnost optimizacije za svaku pojedinu metriku, a X označavaju istorijske vrednosti željenih metrika za određeni dan.
Optimizacija
Cost funkcija se može minimizovati na mnogo načina. Predstaviću vam jednostavnu proceduru prvo, a potom ćemo diskutovati moguća poboljšanja ove ideje. Pohlepan (Greedy) pristup radi ovako:
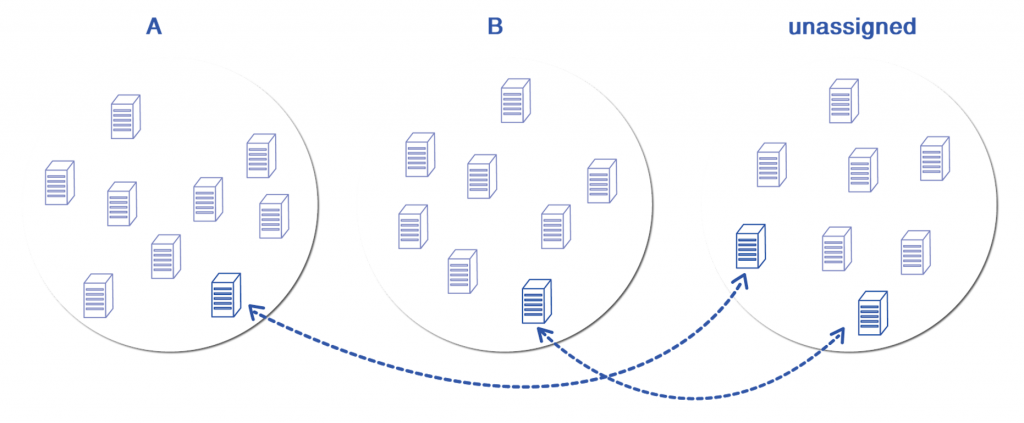
- Počnite sa nasumično inicijalizovanim A, B i Nedodeljenim grupama servera;
- Pronađite jednu (A, Nedodeljeno) ili (B, Nedodeljeno) zamenu mesta servera koji maksimalno smanjuje cost funkciju i izvršite zamenu mesta;
- Ako ne postoji takva zamena, završite i vratite (A, B). U suprotnom, vratite se na korak 2.
Predstavljen je primer sa dve grupe, ali se procedura trivijalno može primeniti i na više od dve test grupe. Jedna iteracija je grafički predstavljena ovde:
Moguće popravke tehnike za optimizaciju:
- Dodajte (A, B) zamene mesta: ovo ne čini proceduru manje pohlepnom, ali bi mogla da ubrza konvergenciju algoritma;
- Dodajte multi-server zamene: umesto zamene mesta pojedinačnih servera, swapujte parove servera; postoji kompromis između brzine i optimalnosti i ovo bi trebalo izučavati od slučaja do slučaja;
- Koristite simulirano kaljenje ili neku drugu proceduru randomizovane optimizacije. Ovo je sve korisnije kako broj servera i grupa raste.
Rezultati merenja
Kako smo evaluirali?
Sad kada imamo ceo algoritam za dodeljivanja servera grupama, spremni smo da obavimo test i evaluiramo kvalitet novog načina uzorkovanja. Da li je procedura bolja od jednostavnog stratifikovanog random uzorkovanja? Ako jeste, koliko? Da li vredi truda?
Ovo evaluiramo koristeći A/A test. Dve grupe moraju biti gotovo jednake po prošlim podacima jer optimizujemo na osnovu njih.
Neformalno, njihove linije na grafiku moraju se skoro potpuno podudarati pre pokretanja testa. Štaviše, moramo proveriti da li su slične tokom A/A testiranja i koliko dugo. To će nam dati informacije o nivou poverenja koji možemo imati u algoritam za selekciju grupa.
Idealno, želeli bismo da grupe ostanu slične dugo vremena nakon uzorkovanja. To bi značilo da nema prepreka u A/B testiranju različitih grupa.
Rezultati
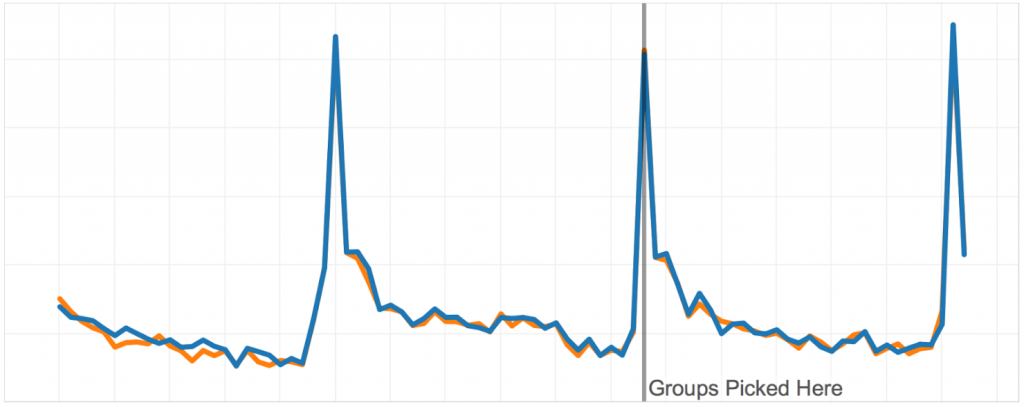
Grafici ispod pokazuju A/A test na dvema grupama optimizovanim na dva meseca podataka iz prošlosti.
Na sledećem grafiku možete videti kako izgleda A/A test sa stratifikovanom random uzorkovanjem. Varijacija je jako velika, a i srednje vrednosti grupa se razlikuju. Ovo značajno ometa analizu testa.
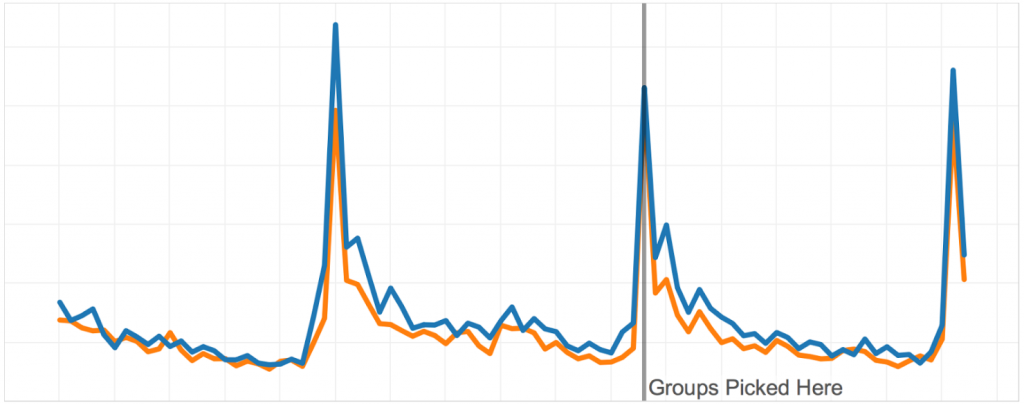
Na grafiku ispod vidite grupe koje smo oformili novim algoritmom. Može se videti koliko su slične grupe na istorijskim podacima na kojima smo optimizovali.
To bi se i očekivalo. Šta je još više kul jeste da grupe ostaju slične nedeljama nakon što smo ih odabrali. To praktično znači da ako primetimo razlike nakon pokretanja testa, možemo biti sigurni da je razlika posledica novih modifikacija igre, a ne statističkog šuma ili sistematske razlike koja je postojala pre A/B testa.
Zaključak
A/B testiranje je sjajan alat za objektivno rešavanje dilema u dizajnu igara i povećavanja playtime-a ili zarade, i na kraju krajeva, stvaranja bolje igre.
Zahtevi A/B testiranja znače da će korisnici biti izloženi različitim setovima kriterijuma. Ipak, ako je vaša igra online PVP, tada je posebno važno biti fer.
Neuspeh u ovome rezultiraće u neravnopravnosti, i integritet vaše igre će biti narušen. Ako vrednujete svoje igrače više od svega drugog, taj integritet je nešto što nikada ne treba shvatiti olako.
U članku sam vam predstavio algoritam kojim biramo test grupe na najbolji mogući način, kako bismo analizu učinili što jednostavnijom i kako bi nam rezultati bili što statistički značajniji. Nadam se da će vam to pomoći da unapredite svoje A/B testove u budućnosti.
Tekst je uz odobrenje autora preveden i uređen za potrebe Startita. Originalni tekst možete pronaći na blogu kompanije Nordeus, ovde.
Nordeus nudi tromesečnu plaćenu praksu za poziciju Backend Developera.
