

Kada je pre par godina Google-ov DeepMind savladao nekoliko Atari igrica učeći kroz trening i na osnovu pogreške — bez prethodne spoznaje koncepata bitnih za igru, recimo loptice, ovaj uspeh je prozvan prvim korakom ka generalnoj veštačkoj inteligenciji.
Ovo je označilo i period u kome podoblast mašinskog učenja — pojačano učenje (reinforcement learning) — prevazilazi prethodne prepreke i uz pomoć napretka dubokog učenja pokazuje više potencijala nego ikada ranije.
Microsoft je prošlog meseca prisvojio kanadski startap Maluuba, a razlog je njihovo iskustvo sa pojačanim i dubinskim učenjem koje će Microsoft iskoristiti za jačanje sopstvenih kapaciteta na polju razumevanja prirodnog jezika, pretraživanja i chatbotova.
Nadgledano, nenadgledano i pojačano učenje
U ovom članku smo preneli detaljno i lepo objašnjeno razlike između nadgledanog i nenadgledanog učenja, ali nije na odmet podsetiti se ukratko razlika — a potom i uporediti sa pojačanim učenjem.
Uglavnom svi prodori u mašinskom učenju o kojima pišemo i čitamo, a koji se pretenciozno nazivaju "veštačkom inteligencijom", učinjeni su posredstvom tzv. nadgledanog učenja (supervised learning). U ovom slučaju imamo klasifikatore sačinjene od inputa X i autputa, cilja, Y. Algoritam uz naš nadzor uči da mapira funkciju od ulaza ka izlazu tako da je:
Y = f(X)
U svakom koraku nadgledamo ovaj proces i znamo tačne vrednosti Y, a u slučaju greške ispravljamo algoritam sve dok ne zadovolji željeni cilj.
U slučaju nenadgledanog učenja, mašina ne dobija našu povratnu informaciju, a zadatak joj je da predstavi inpute na što efikasniji način; to čini kroz uočavanje obrazaca, a dobar primer za ovo su kompleksni vizuelni inputi koje pojednostavljuje kroz uočavanje regularnosti poput kontinuiteta ivice ili boje u određenim regionima.
Pojačano učenje je bliže nadgledanom učenju, s tim da povratna informacija nije ispravka, već obaveštenje da je došlo do greške. Kroz pokušaj i pogrešku nastoji da dostigne najvišu nagradu u sistemu, čak i ako se to ne desi odmah. Radi se o rešavanju problema i pronalasku najefikasnijeg rešenja — u primeru Breakout-a, kopanje tunelčića u uglu.
https://www.youtube.com/watch?v=Ee4uH7PaN1M&feature=youtu.be&t=2m15s
Šta stoji iza pojačanog učenja?
Dva bitna koncepta za razumevanje implementacije pojačanog učenja su Markovljev proces odlučivanja i Q-učenje.
Markovljev proces odlučivanja sadrži:
set stanja S;
set akcija A;
funkcije nagrade R;
verovatnoću P da će akcija a u stanju s u vremenu t rezultirati stanjem s' u vremenu t + 1;
trenutnu (ili očekivanu trenutnu) nagradu R primljenu nakon prelaska iz stanja s u s' usled akcije a;
diskontni faktor, odnosno razliku u vrednosti između buduće nagrade i sadašnjeg stanja;
a osnovni problem koji teži rešiti jeste da pronađe princip za donošenje odluka — odnosno akciju koju će akter odabrati u stanju s — tako da maksimizuje kumulativnu nagradu. Dobar primer je takozvani problem putujućeg prodavca gde nam je zadatak da odemo od tačke A do tačke F uz što manji trošak (brojevi između dva čvora označavaju "cenu" prelaska određenog puta — pozitivni brojevi su ono što plaćamo, a negativni ono što zaradimo).
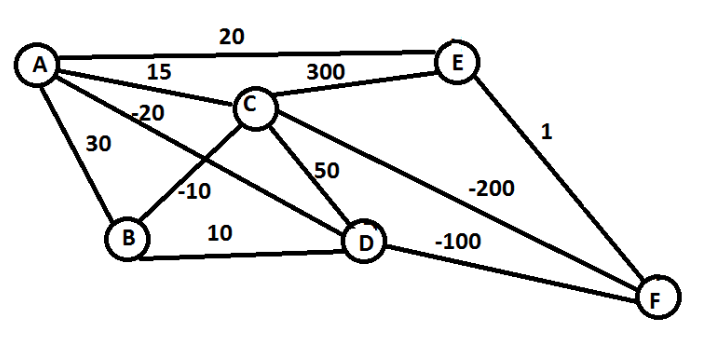
Pohlepni algoritmi, porodica algoritama koja se koristi u pojačanom učenju, ići će stazom A - D - F, jer od A i D do narednog čvora upravo ovom putanjom najviše zarađuje/najmanje plaća. Te odluke su u tom čvoru najbolje trenutno rešenje i daju najveću nagradu.
Q-učenje je ono što omogućava akteru da uči iz iskustva, odnosno posle niza pokušaj-pogreška-pokušaj-nagrada epizoda, akter uči najoptimalniju rutu. Matrica Q je mozak, koji treniranjem i pokušajem koji se završava greškom ili nagradom ojačava sposobnosti odlučivanja tako da dođe do ciljanog stanja.
Dostignuća pojačanog učenja
Breakout je među igricama na kojima je DeepMind testirao spoj pojačanog učenja i dubinskog učenja (deep Q-network), prešišavši nivo uspešnosti prethodnih algoritama (i ljudi). DQN je kao inpute dobio samo piksele i rezultate igre, a ne prethodno programirane koncepte; ovo je bitno drugačije od, recimo, IBM-ovog Watson-a u čijem slučaju ljudi hrane mašinu terabajtima i terabajtima podataka.
Pojačano učenje testirano je i u nekoliko oblasti sem video igara, uključujući robotiku, ekonomiju, autonomnu kontrolu vozila, interakcije ljudi i kompjutera (HCI). Neke od uspešnih implementacija desile su se još 80-ih i 90-ih, kao recimo automatizacija rada lifta (1996) i kontrola opterećenosti spejs šatla (1996).
Google je prošle godine počeo da koristi DeepMind-ovo pojačano učenje kako bi uštedeo energiju u svojim centrima za podatke — ostvarili su poboljšanja energetske efikasnosti od 15%. Microsoft takođe testira mogućnosti tehnologije, pa su 2016. počeli da koriste podskup pojačanog učenja za generisanje personalizovanih naslova na MSN.com.
Marija Gavrilov
subota, 18. Februar, 2017.
Hvala ti na komentaru, Nenade! Ostale članke vezane za razvoj veštačke inteligencije možeš pronaći ovde: http://startit.rs/ai-vestacka-inteligencija-2/ Što se prevoda tiče, slažem se da zvuči suboptimalno. No, pronašla sam stručne radove u kojima se ovako prevodi, te sam odlučila da (bar za sada) tako ostane. Ako imaš bolju sugestiju, I'm all ears :)
Nenad
subota, 18. Februar, 2017.
Fino je videti da se i kod nas sve više piše o napretku na polju veštačke inteligencije. Nadam se da će se taj trend nastaviti. Uzgred, da li je 'pojačano učenje' zvanična terminologija na srpskom? Meni lično ne zvuči kao sasvim pravilan prevod. Nije učenje samo po sebi 'pojačano' nečim, već se radi o učenju putem ojačavanja-učvrščivanja korisnih obrazaca. Nisam imao prilike čitati srpske tekstove o tome, tako da ne znam da li je možda neko drugačije prevodio ranije.