
Ilustracija: Latent Space
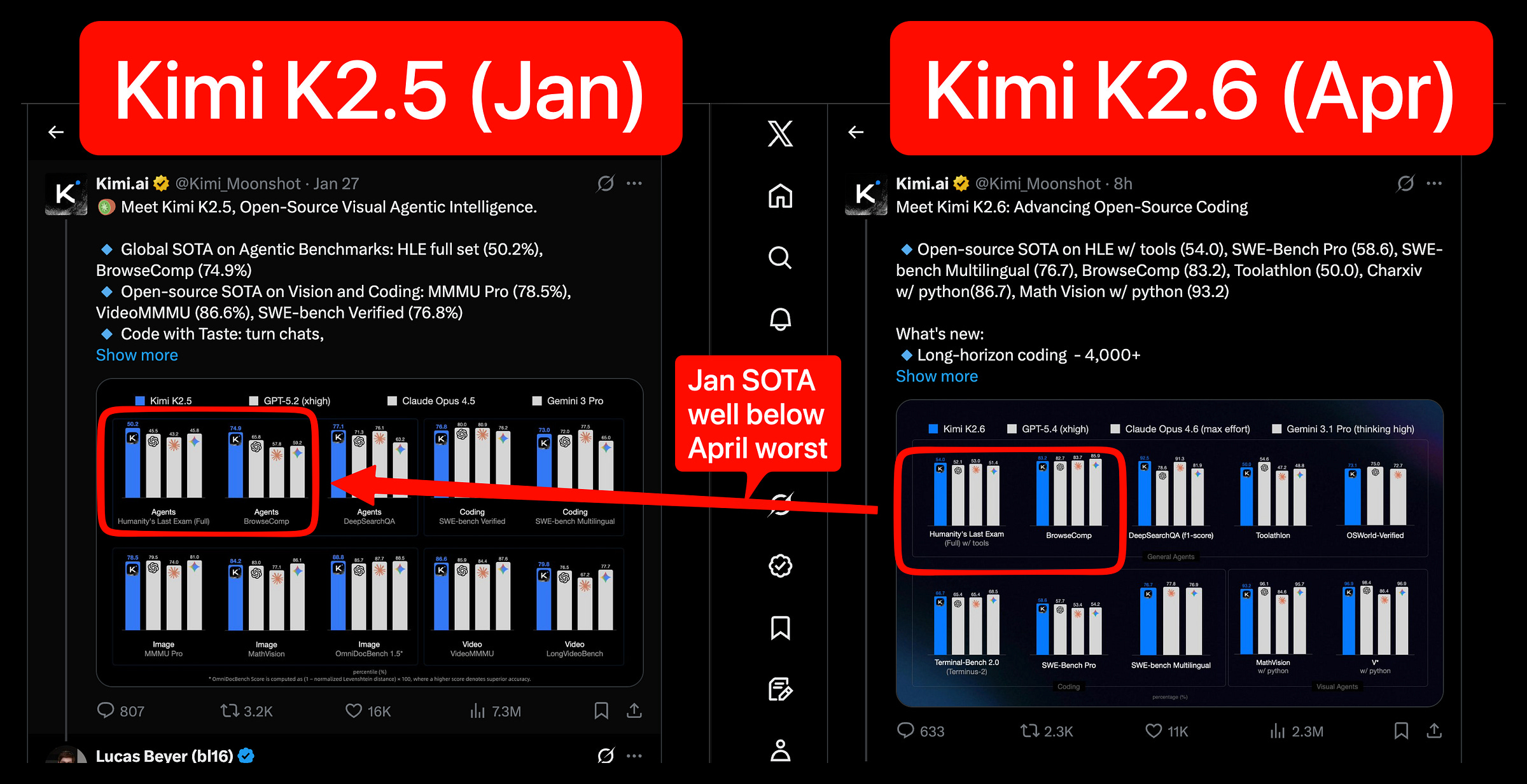
Kineski AI lab Moonshot AI objavio je Kimi K2.6, MoE model sa bilion parametara koji na rezultatima za programiranje nadmašuje i Opus 4.6 i GPT-5.4, a košta oko 9 puta manje.
Težine modela, 32 milijarde aktivnih parametara po tokenu, su na Hugging Faceu pod modifikovanom MIT licencom — model možete koristiti maltene kakogod hoćete. Na SWE-Bench Pro testu za rešavanje GitHub issuea, K2.6 vodi ispred oba modela, a prednost drži i na HLE testu sa alatima.
Kako primećuje Latent Space, januarski SOTA rezultati (K2.5 generacija) su sada ispod najgoreg modela u aprilskom poređenju — za tri meseca se ceo pod podigao toliko da prethodni šampion ne bi prošao ni kao najslabiji.
Rezultati vs. praksa
Sa svakim kineskim modelom koji objavi dobre rezultate nameće se pitanje koliko se to prenosi u svakodnevnu upotrebu. Modeli poput DeepSeeka i Qwena su nas naučili da impresivni brojevi ne znače automatski sofisticiraniji model u kompleksnim zadacima.
How are people feeling actually using Kimi K2.6 for code?
— Theo - t3.gg (@theo) April 20, 2026
Tehnički detalji su ipak ozbiljni — arhitektura koristi 384 eksperta od kojih se 8 aktivira po tokenu, sa kontekstom od 256K tokena i nativnom multimodalnom podrškom. Jedna od zanimljivijih demonstracija je autonomna optimizacija osmogodišnjeg koda jednog berzanskog sistema.
Sistem je za 13 sati napravio 4000+ poziva alata kroz 12 iteracija optimizacije i skoro utrostručio brzinu obrade transakcija. Model može da koordiniše do 300 pod-agenata u 4000 koraka istovremeno.
Kimi-K2.6 SWE-Bench-Pro results are ridiculous https://t.co/lwHL54TWdh
— Lisan al Gaib (@scaling01) April 20, 2026
Ono što privlači posebnu pažnju je cena: $0.60 po milion ulaznih tokena i $2.80 po milion izlaznih, naspram $5 i $25 kod Opusa 4.6. Za timove koji troše ozbiljne količine tokena na coding agente, razlika je značajna.
When I saw our team's evals of Kimi 2.6, I thought "ok, things are gonna get interesting now".
This is the first open-weight model that plays like a top-class agentic model. Watching it go through ambiguous and meticulous chained tool work successfully puts it squarely in the… https://t.co/WB3TUyXxOV
— Sarah Sachs (@sarahmsachs) April 21, 2026
Model se koristi preko kimi.com i API-ja, a težine su na Hugging Faceu za lokalno pokretanje. Bez obzira na to koliko se kineski modeli pokažu u praksi, open-weights alternativa ovog kalibra po ovoj ceni je dobra vest za sve nas.